Stock Price Prediction with BERT
In my Data Science thesis project, I developed a model able to predict the Natural Gas
stock price based on the topical news published daily on Reuters and the historical
time series of the price. Here you can find a summary of the project while on my GitHub page, you can find the integral version.
This project merges various techniques a Data Scientist should have.
Firstly, I scraped headlines and summaries from Reuters, a journalistic online agency.
Then, I applied both Natural Language Processing and Time Series techniques alternating
machine learning, deep learning, and statistical methods.
In addition, I performed Twitter scraping and streaming to collect all the posts published during 2022 about
the invasion of Ukraine and Gas Natural.
Finally, I applied state-of-the-art comparison methodologies to select the best model
among the ones chosen.
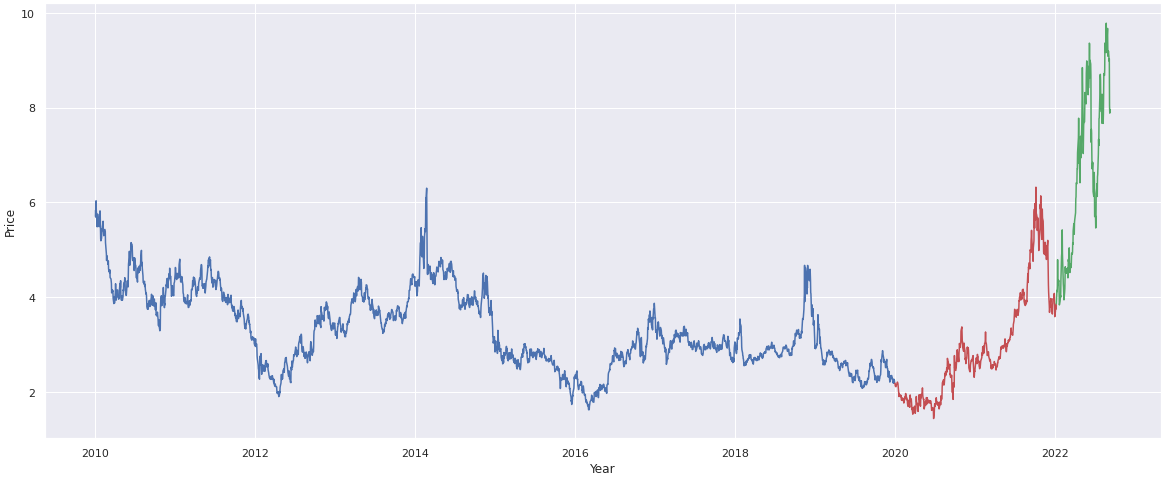
The Russian invasion of Ukrainian territory led to serious consequences all over Europe.
Among them, the gas price growth brought many European countries to revisit their policy.
This growth pushed the stock price to levels never recorded before. This is the reason why
I chose to face this problem as a thesis project.
The heart of this project was the development of a BERT model able to forecast the stock price
as accurately as possible. BERT is Language Model created to accomplish different tasks compared
to this. The application of some architectural changes transformed the problem into a regression one.
Besides, the usage of a Rolling Cross Validation allowed the model to handle sequential data.
Two BERT alternatives were proposed to solve the task: DistilBERT and FinBERT.
The first is a light version of BERT which keeps 97% of prediction power.
The second is a variant pre-trained on financial data. After various attempts discussed in the thesis,
the best model was DistilBERT trained with the following features: the daily processed news,
the moving average of the price, and the output of the Financial Sentiment Analysis performed on the same news.
The introduction of a numeric feature as input for BERT models was a great step forward since these kinds of
models only process textual data.
I also selected two baseline models to have a benchmark with whom to compare the major models.
These models were a statistical model ARIMA and a Random Forest. The Rolling Cross Validation and
some structural transformations applied to the dataset allowed me to compare properly all the models trained.
In the end, the best model cited above was tested on the 2022 set which was the year that registered
new stock price values. The models initially struggled then thanks to the division in multiple folds
it could adapt itself to new observations and consequently reduce the error.